Indexierung
Als Indexierung wird die Aufnahme einer Webseite in den Index einer Suchmaschine bezeichnet. Dabei analysieren Crawler einer Suchmaschine alle Informationen und Daten der Webseite und speichern diese in ihrer eigenen großen Datenbank ab.
Was bedeutet Indexierung?
Als Indexierung wird der Moment bezeichnet, in dem eine Suchmaschine eine Webseite offiziell in ihr Verzeichnis aufnimmt. Erst durch diesen Schritt existiert die Seite für die Suchmaschine und kann bei passenden Suchanfragen in den Ergebnissen ausgespielt werden. Man kann es sich wie einen digitalen Bibliothekskatalog vorstellen: Nur wer im Register steht, kann von den Lesern auch im Regal gefunden werden.
Wie geht Google bei der Indexierung vor?
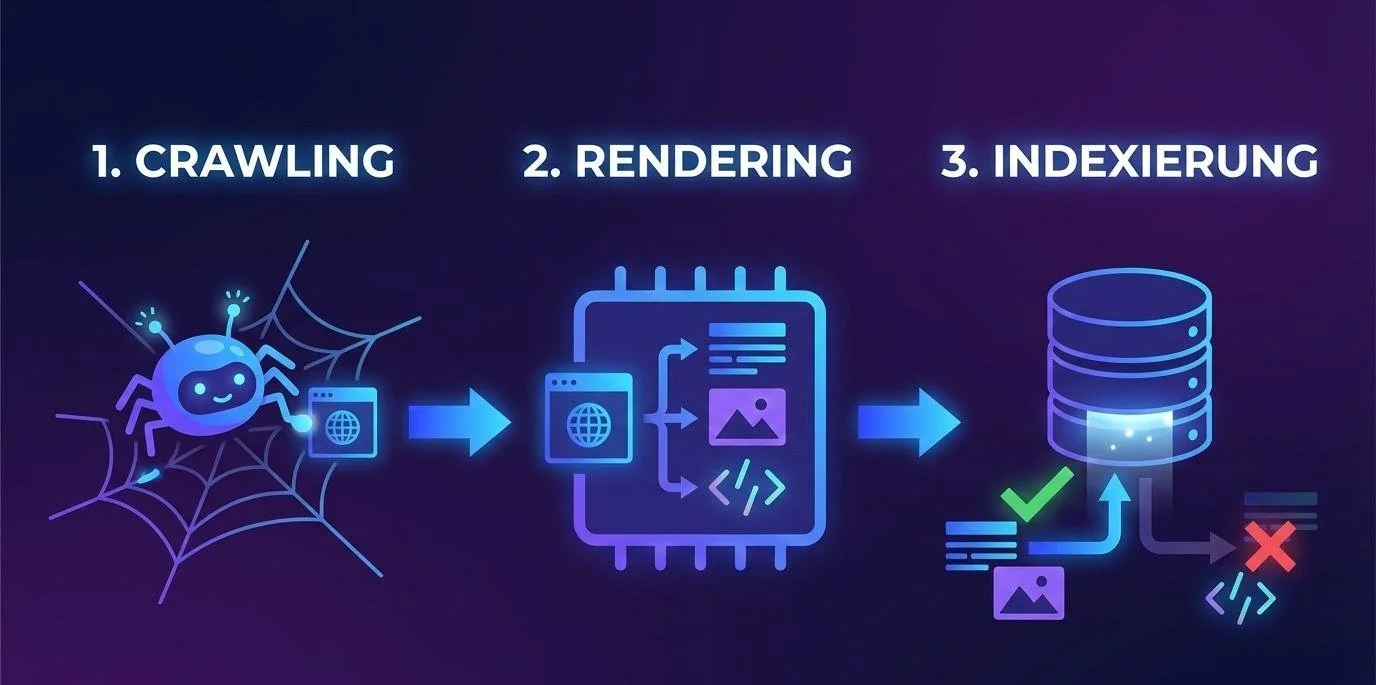
Crawling: Das Entdecken neuer Welten
In der ersten Phase schickt Google automatisierte Programme los, die sogenannten Crawler oder Bots (oft auch „Googlebot“ genannt). Diese Bots bewegen sich wie kleine Entdecker durch das Internet. Sie folgen Links von einer Seite zur nächsten. Sobald sie eine neue URL finden, die sie noch nicht kennen, besuchen sie diese. Man kann sich das Crawling wie das Sichten von neuen Büchern für eine Bibliothek vorstellen: Der Bibliothekar schaut nach, was es Neues auf dem Markt gibt.
Rendering: Den Inhalt verstehen und “ansehen”
Früher hat Google nur den reinen Text einer Seite gelesen. Heute ist das anders: Beim Rendering lädt Google die Webseite fast so, wie ein echter Nutzer sie in seinem Browser (z. B. Chrome oder Safari) sehen würde. Die Suchmaschine setzt alle Einzelteile der Seite zusammen. Dazu gehören Texte, Bilder, Formatierungen und auch Skripte. Dieser Schritt ist extrem wichtig, damit Google versteht, ob die Seite benutzerfreundlich ist, ob sie auf dem Handy gut aussieht und welche Informationen für den Leser wirklich im Vordergrund stehen.
Indexierung: Die Aufnahme ins Archiv
Erst wenn der Inhalt verstanden wurde, folgt die eigentliche Indexierung. Google entscheidet nun, ob die Seite einen dauerhaften Platz im Verzeichnis verdient hat. Wenn die Qualität stimmt und keine technischen Fehler vorliegen, wird die Seite in der gigantischen Datenbank gespeichert. Ab diesem Moment ist die Webseite „live“ im Index. Wenn nun ein Nutzer nach einem passenden Begriff sucht, muss Google nicht mehr das ganze Internet durchforsten, sondern schaut blitzschnell in seinem eigenen, sortierten Index nach und spielt die Seite aus.
Einmal drin, heißt nicht immer drin:
Google besucht indexierte Seiten in regelmäßigen Abständen erneut. Wenn sich Inhalte zum Negativen verändern oder deine Seite plötzlich extrem langsam lädt, kann sie ihren Platz im Index auch wieder verlieren oder weiter hinten platziert werden.
Status-Check:
Wie kann ich die Google Indexierung prüfen?
Um herauszufinden, ob eine URL bereits im Verzeichnis gelistet ist, gibt es zwei bewährte Wege:
Google Search Console:
Über das Tool zur URL-Prüfung lässt sich eine exakte Diagnose abrufen. Hier wird direkt angezeigt, ob die Seite indexiert ist und wann der Bot sie das letzte Mal besucht hat. Außerdem werden dir hier auch eventuelle Indexierungsfehler, die Anzahl der indexierten Seiten und Probleme mit manuellem Handlungsbedarf aufgelistet. Zur Google Search Console ⟫
Die „Site:“-Abfrage:
Wenn man direkt in das Suchfeld von Google den Befehl site:deinedomain.de/unterseite eingibt, sieht man sofort das Ergebnis. Erscheint die Seite in der Liste, ist sie im Index. Bleibt die Ergebnisliste leer, fehlt der Eintrag noch.
Wie kann ich meine Website bei Google indexieren lassen?
Obwohl die Suchmaschine unermüdlich das Netz durchstreift, lässt sich der Prozess auch aktiv steuern und beschleunigen. Je nachdem, wie eilig es ist und wie technisch versiert du dich fühlst, stehen verschiedene Wege zur Verfügung:
Die XML-Sitemap (Der Klassiker)
Eine Sitemap ist im Grunde ein Inhaltsverzeichnis deiner Webseite in Code-Form. Diese Datei hinterlegst du in der Google Search Console.
Vorteile: Google erhält eine strukturierte Liste aller URLs und übersieht keine Unterseiten, selbst wenn diese intern schlecht verlinkt sind. Es ist eine „Einmal einrichten und vergessen“-Lösung, da sich moderne Sitemaps automatisch aktualisieren.
Nachteile: Es gibt keine Garantie, dass Google alle URLs sofort crawlt, nur weil sie in der Sitemap stehen. Bei sehr großen Webseiten kann es dennoch dauern, bis der Bot jede Ecke besucht hat.
Manuelle Indexierung (Express-Weg)
Wenn du einen neuen Blogartikel veröffentlicht oder eine wichtige Seite aktualisiert hast, kannst du die URL direkt in das Prüftool der Google Search Console eingeben und auf „Indexierung beantragen“ klicken.
Vorteile: Dies ist der schnellste Weg, um Google auf eine Änderung aufmerksam zu machen. Oft erscheint die Seite so innerhalb weniger Minuten oder Stunden in den Suchergebnissen.
Nachteile: Der Vorgang ist zeitaufwendig, da man jede URL einzeln eingeben muss. Zudem gibt es ein tägliches Limit für manuelle Anfragen, weshalb sich dieser Weg nicht für hunderte neue Seiten gleichzeitig eignet.
Interne Verlinkung (Natürlicher Weg)
Indem du von einer bereits gut besuchten und indexierten Seite (wie deiner Startseite) auf eine neue Unterseite verlinkst, leitest du den Googlebot direkt dorthin.
Vorteile: Das wirkt für die Suchmaschine besonders natürlich und stärkt gleichzeitig die Struktur deiner Webseite. Es verbessert nicht nur die Indexierung, sondern auch die allgemeine Nutzererfahrung.
Nachteile: Bei sehr tief verschachtelten Menüs oder versteckten Links kann es länger dauern, bis der Crawler den Weg zur neuen Seite findet.
Die Mischung macht's:
Für den dauerhaften Erfolg empfiehlt es sich, eine Sitemap zu hinterlegen, damit Google das Grundgerüst kennt. Für besonders wichtige News oder neue Produkte sollte man zusätzlich den manuellen Weg wählen, um keine Zeit zu verlieren. In der Google-Dokumentation findest du dazu noch weitere Hinweise.
Wie lange dauert die Indexierung bei Google?
Es gibt keine feste Garantie für die Dauer, bis deine Webseite in den Suchergebnissen auftaucht. Bei etablierten Webseiten mit hoher Autorität geschieht die Indexierung oft innerhalb weniger Stunden. Bei neuen Projekten kann es hingegen einige Tage oder in Einzelfällen sogar Wochen dauern. Die Geschwindigkeit hängt stark von der Qualität des Inhalts und dem sogenannten Crawl-Budget ab. Google weist jeder Webseite eine begrenzte Zeitspanne zu, die der Bot dort verbringt. Je schneller und strukturierter eine Seite lädt, desto mehr Inhalte kann Google in dieser Zeit erfassen.

Häufigste Probleme bei der Indexierung
Es kann frustrierend sein, wenn hochwertige Inhalte erstellt wurden, Google diese aber scheinbar ignoriert. Meist steckt einer der folgenden Gründe dahinter:
Technische Blockaden (robots.txt & noindex):
Dies ist der häufigste Fehler. Oft wurde während der Entwicklungsphase der Seite ein „noindex“-Tag gesetzt, um zu verhindern, dass die Baustelle bei Google erscheint. Wird dieser Tag beim Livegang vergessen, bleibt die Seite für Google unsichtbar. Auch eine zu streng konfigurierte robots.txt kann den Crawler komplett aussperren.
Mangelnde Inhaltsqualität (Thin Content):
Google möchte seinen Nutzern nur die besten Ergebnisse liefern. Wenn eine Seite extrem wenig Text bietet oder der Inhalt keinen echten Mehrwert darstellt, entscheidet sich die Suchmaschine oft gegen eine Indexierung. Qualität schlägt hier eindeutig Quantität.
Duplicate Content (Doppelte Inhalte):
Wenn der gleiche Text bereits auf einer anderen Unterseite oder einer fremden Domain existiert, sieht Google keinen Grund, diese URL zusätzlich in den Index aufzunehmen. Die Suchmaschine wählt in der Regel nur eine Version aus, die als „Original“ (kanonisch) gilt.
Fehlende interne Verlinkung:
Der Googlebot hangelt sich von Link zu Link. Wenn eine neue Seite von keiner anderen Stelle der Website aus verlinkt wird, ist sie eine sogenannte „Orphan Page“ (Waisenseite). Der Crawler findet sie schlichtweg nicht, es sei denn, sie wird manuell eingereicht.
Crawl-Fehler und Serverprobleme:
Wenn der Server zum Zeitpunkt des Besuchs durch den Googlebot überlastet ist oder Fehlermeldungen (wie den Statuscode 500) ausgibt, bricht der Crawler den Vorgang ab. Passiert das häufiger, stuft Google die Seite als unzuverlässig ein.
"Gecrawlt, zurzeit nicht indexiert":
Diesen Status liest man oft in der Search Console. Er bedeutet: Google war da und hat die Seite gesehen, hält sie aber momentan nicht für wichtig genug für den Index. Die Lösung ist hier meist eine deutliche Verbesserung der Inhaltsqualität oder eine stärkere interne Verlinkung.
Indexierung verhindern oder rückgängig machen:
Es gibt gute Gründe, warum bestimmte Seiten nicht in der Google-Suche auftauchen sollten, wie etwa interne Testbereiche oder Login-Masken. Damit Suchende nicht an interne Firmendaten, Kunden-Interfaces etc. gelangen, gibt es folgende Möglichkeiten, eine natürliche Indexierung zu verhindern und rückgängig zu machen:
Die robots.txt Datei als erster Wegweiser:
Diese kleine Textdatei liegt im Hauptverzeichnis der Domain und ist die erste Anlaufstelle für jeden Crawler. Man kann sie sich wie einen Pförtner vorstellen, der festlegt, welche Bereiche der Website (z. B. der Login-Bereich oder Systemordner) für Bots tabu sind. Dies spart wertvolles Crawl-Budget, damit Google sich auf die wirklich wichtigen Inhalte konzentriert. Ein falscher Befehl hier kann jedoch dazu führen, dass die gesamte Seite versehentlich für Google gesperrt wird. Frage im Ernstfall lieber deinen SEO-Manager nach einer ersten Einschätzung.
Indexierung verhindern:
Während die robots.txt nur den Zutritt regelt, ist der „noindex-Tag“ im Quellcode einer Seite die explizite Anweisung, diese URL nicht in das öffentliche Verzeichnis aufzunehmen. Dies ist der sicherste Weg für rechtliche Seiten wie das Impressum oder für Testumgebungen. In der Regel bieten alle modernen CMS-Systeme und Website-Baukästen speziell dafür eine eigene Funktion an, ob der Inhalt in den Suchergebnissen auftauchen soll.
Indexierung rückgängig machen:
Falls eine Seite versehentlich indexiert wurde, lässt sie sich über das Tool zum Entfernen in der Search Console kurzfristig ausblenden. Damit sie dauerhaft verschwindet, sollte sie anschließend mit einem „noindex-Tag“ versehen werden. Auch Indexierungen, welche schon lange in der Vergangenheit liegen, können mit dieser Möglichkeit aus den SERPs gelöscht werden. (Ja, auch unangenehme Mitarbeitershootings aus dem Gründungsjahr 😜)
Kann die manuelle Indexierung Strafen nach sich ziehen?
Nein, hier besteht kein Grund zur Sorge. Die manuelle Beantragung der Indexierung über die offiziellen Google-Tools führt niemals zu einer Abstrafung. Es ist ein ganz normaler Bestandteil der Suchmaschinenoptimierung und hilft Google lediglich dabei, Prioritäten bei der Erfassung neuer Inhalte zu setzen.
Google beschränkt allerdings die Anzahl der manuellen Anfragen pro Tag über die Search Console auf etwa 10-15 URLs pro Tag. Wenn du versuchst, hunderte Seiten manuell einzureichen, wirst du irgendwann eine Fehlermeldung („Kontingent erschöpft“) erhalten. Dies ist aber keine Strafe, sondern lediglich eine kleine Sperre für weitere manuelle Anfragen pro Tag.
Möchtest du viele Seiten auf einmal indexieren, ist das Einreichen einer Sitemap definitiv die bessere Wahl.
Empfehlung bei Technical SEO:
Da technische Anpassungen an der Indexierung das „Herzstück“ der Sichtbarkeit berühren, kann ein kleiner Fehler hier große Auswirkungen haben. Bei Unsicherheiten in der Konfiguration der robots.txt oder bei komplexen Indexierungsproblemen ist es oft ratsam, kurz Rücksprache mit einem SEO-Manager oder Webmaster zu halten, um die dauerhafte Erreichbarkeit der Seite abzusichern.
Die häufigsten Fragen zur Indexierung:
-
Am einfachsten stößt man die Aktualisierung an, indem man die betroffene URL erneut in der Google Search Console zur Indexierung einreicht. Der Bot besucht die Seite dann zeitnah erneut und ersetzt den alten Stand im Verzeichnis durch die neuen Informationen.
-
Oft liegen technische Hindernisse vor, wie ein versehentliches Verbot in der robots.txt Datei oder ein falsch gesetzter noindex Tag. Auch eine sehr langsame Ladezeit oder minderwertige Inhalte können dazu führen, dass Google die Seite ignoriert.
-
Ja, das ist möglich. Man kann den Zugriff auf Bilderordner gezielt über die robots.txt Datei sperren. So tauchen Grafiken oder private Fotos nicht in der Bildersuche auf, während die Texte der Webseite weiterhin normal gefunden werden können.